Définition
Le fichier robots.txt est un fichier texte qui indique aux robots d'indexation s’ils doivent ou non indexer certaines pages. C’est le gardien de l'ensemble de votre site internet. L’objectif premier des robots d'exploration est de trouver et de lire ce fichier robots.txt, avant d'accéder à votre site ou à tout autre dossier ou page.
Avec le fichier robots.txt, vous pouvez :
- Réguler la façon dont les robots des moteurs de recherche explorent votre site.
- Accorder certains accès.
- Aider les robots des moteurs de recherche à indexer le contenu d’une page.
- Indiquer comment présenter le contenu aux utilisateurs.
Le fichier Robots.txt fait partie du protocole d'exclusion des robots (aussi appelé R.E.P.). Ce protocole comprend les directives du site, de la page et de l'URL. Les robots des moteurs de recherche peuvent toujours explorer votre site internet dans son intégralité, mais vous devez les aider à déterminer si certaines pages valent la peine d’être inspectées ou non.
Pourquoi avez-vous besoin de Robots.txt ?
Votre site peut très bien fonctionner sans fichier robots.txt. Si vous avez besoin d’un fichier robot.txt, c’est essentiellement parce que, lorsque les robots explorent votre page, ils demandent l'autorisation d'explorer le site pour y récupérer des informations sur la page à indexer. Par ailleurs, si un site internet n’a pas de fichier robots.txt, les robots peuvent indexer le site en question comme ils l'entendent. Il faut bien comprendre que les robots exploreront votre site même si celui-ci ne dispose pas de fichier robots.txt.
L'emplacement de votre fichier robots.txt est lui aussi particulièrement important car tous les robots recherchent www.123.com/robots.txt. S'ils ne trouvent rien à cet emplacement, ils en déduiront que le site ne possède pas de fichier robots.txt et ils l’indexeront intégralement. Le fichier doit être un fichier texte ASCII ou UTF-8. Il est également important de noter que les règles sont sensibles à la casse.
Voici ce que robots.txt peut et ne peut pas faire:
- Le fichier peut contrôler l'accès des crawlers à certaines zones de votre site internet. Il faut être particulièrement prudent lorsque l’on configure le fichier robots.txt, car il est possible de bloquer l'indexation du site internet dans son intégralité.
- Grâce à lui, le contenu qui est en double n’est pas indexé et n’apparaît pas dans les résultats des moteurs de recherche.
- Le fichier précise le délai d'indexation pour éviter de surcharger les serveurs lorsque les robots chargés de l’indexation chargent plusieurs éléments de contenu simultanément.
Voici quelques robots Google susceptibles de parcourir votre site de temps à autre :
| Robot d’indexation | Chaîne User-Agent |
| Googlebot News | Googlebot-News |
| Googlebot Images | Googlebot-Image/1.0 |
| Googlebot Video | Googlebot-Video/1.0 |
| Google Mobile (téléphone) | SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (compatible; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Google Smartphone | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (compatible; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | Mediapartners-Google |
| Google AdsBot (qualité des pages de renvoi PPC) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Google app crawler (récupération des ressources pour les mobiles) | AdsBot-Google-Mobile-Apps |
Vous pouvez trouver davantage de bots ici.
- Ces fichiers précisent l'emplacement des sitemaps.
- Ils empêchent également les robots des moteurs de recherche d'indexer divers fichiers sur le site internet, tels que les PDF et les images.
Lorsqu'un robot veut inspecter votre site internet (par exemple, www.123.com), il commence par rechercher www.123.com/robots.txt et voici ce qu’il trouve :
User-agent : *
Disallow : /
Ceci empêche les robots des moteurs de recherche (User-agents*) d’indéxer (Disallow : /) le site internet.
Si vous enlevez la barre oblique « disallow », comme dans l'exemple ci-dessous,
Utilisateur-agent : *
Disallow :
Alors les robots pourront explorer et indexer tous les éléments du site internet. C'est pourquoi il est primordial de comprendre la syntaxe de robots.txt.
Comprendre la syntaxe de robots.txt
On peut assimiler la syntaxe de robots.txt à un « langage » que parleraient les fichiers robots.txt. Cinq termes sont particulièrement courants, et il est très probable que vous les rencontriez dans un fichier robots.txt. Voici les termes en question :
- User-agent : ce sont les robots d'exploration des moteurs de recherche spécifiques (généralement un moteur de recherche). C’est à eux que vous communiquez les instructions relatives à l'exploration du site internet. Vous pouvez trouver la plupart des user-agents ici.
- Disallow : cette commande indique à un user-agent qu’il ne doit pas inspecter une page URL particulière. Une URL ne peut compter qu’une seule ligne « disallow ».
- Allow (pour Googlebot seulement) : cette commande permet à Googlebot d’accéder à une page ou à un sous-dossier, même si l’accès à la page ou au sous-dossier parent n'est pas autorisé.
- Crawl-delay : la durée d’attente en millisecondes nécessaire au robot d'exploration avant de charger et d'explorer le contenu d’une page internet. Googlebot ne reconnaît pas cette commande, mais le taux d'exploration peut être fixé dans Google Search Console.
- Sitemap : utilisé pour l'emplacement de tout sitemap XML associé à une URL. Cette commande n'est prise en charge que par Google, Ask, Bing et Yahoo.
Les résultats de l'instruction Robots.txt
Il y trois résultats différents que vous devez attendre lorsque vous fournissez des instructions robots.txt :
- Full allow
- Full disallow
- Conditional allow
Examinons chacune d'entre elles ci-dessous.
Full allow
Ceci indique que l’intégralité de votre site internet peut être inspectée. Le rôle des fichiers robots.txt consiste à bloquer l'exploration du site par les moteurs de recherche. Cette commande peut donc s’avérer très utile.
Ce résultat peut signifier que votre site internet ne dispose pas de fichier robots.txt. Même si vous n’en avez pas, les robots des moteurs de recherche essaieront de le trouver, et s’ils n’en trouvent pas, ils exploreront tout votre site internet.
Une autre option consiste à créer un fichier robots.txt vide. Lorsque les bots voudront explorer le site, ils localiseront ce fichier et ils pourront même le lire, mais comme ils n’y trouveront aucune instruction, ils poursuivront l’exploration du site internet.
Si vous avez un fichier robots.txt contenant ces deux lignes :
User-agent:*
Disallow :
le bot du moteur de recherche explorera le site internet, identifiera le fichier robots.txt et le lire. Il ira jusqu'à la deuxième ligne puis procédera à l'exploration du site.
Full disallow
Dans ce cas, le contenu ne sera ni crawlé, ni indexé. Cette commande est émise par cette ligne :
User-agent:*
Disallow:/
Pour être plus clair, aucun élément du site internet, ni contenu, ni page, etc. ne sera alors être exploré. Ceci n'est jamais une bonne idée.
Conditional Allow
Cette commande autorise l’exploration d’une partie du site seulement.
Conditional allow se présente sous ce format :
User-agent:*
Disallow:/
User-agent: Mediapartner-Google
Allow:/
Vous pouvez consulter la syntaxe complète de robots.txt ici.
Veuillez noter que les pages bloquées peuvent être indexées, et ce même si vous avez désactivé l'URL, comme vous pouvez le voir sur l'image ci-dessous :
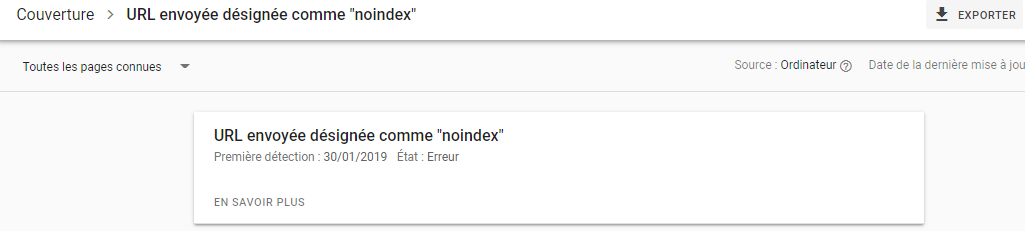
Vous recevrez peut-être un email des moteurs de recherche pour vous informer que votre URL a été indexée, comme dans la capture d'écran ci-dessus. Si une URL de votre site internet rattachée à d'autres sites a été rejetée, comme un texte d'ancrage dans les liens, elle sera indexée. La solution consiste à 1) protéger vos fichiers grâce à un mot de passe sur votre serveur, 2) utiliser la balise méta noindex, ou bien 3) supprimer toute la page.
Un robot peut-il parcourir et ignorer mon fichier robots.txt ?
Tout à fait. Un robot peut contourner le fichier robots.txt. En effet, Google utilise d'autres facteurs (comme les informations externes ou les liens entrants), pour déterminer si une page doit être indexée ou non. Si vous ne désirez pas du tout qu'une page soit indexée, vous devez utiliser la balise méta robots noindex. Une autre option consiste à utiliser l'en-tête HTTP X-Robots-Tag.
Puis-je bloquer les mauvais robots seulement ?
En théorie, il est tout à fait possible de bloquer les mauvais robots. Toutefois, en pratique, ça peut être difficile. Voyons ensemble comment y parvenir :
- Vous pouvez exclure un mauvais robot. Toutefois, vous devez connaître le nom utilisé par ce robot dans le champ User-Agent lors du scan. Vous devez alors ajouter une section à votre fichier robots.txt pour exclure le robot en question.
- La configuration du serveur. Cette solution ne fonctionne que si le robot opère à partir d'une adresse IP unique. C’est alors la configuration du serveur ou le pare-feu réseau qui empêchera le robot d'accéder à votre serveur internet.
- Vous pouvez modifier les configurations avancées du pare-feu. Celles-ci bloqueront automatiquement l'accès aux différentes adresses IP qui pourraient contenir des copies du robot malveillant. Un bon exemple de robots opérant à partir de plusieurs adresses IP est celui des PC détournés qui peuvent même faire partie d'un botnet plus important (pour en savoir plus sur les botnets, cliquez ici).
Si le robot malveillant opère à partir d'une seule adresse IP, vous pourrez l’empêcher d’accéder à votre serveur internet via la configuration du serveur ou avec un pare-feu réseau.
Si des copies du robot opèrent à partir de plusieurs adresses IP différentes, il devient plus difficile de les bloquer. La meilleure chose à faire dans ce cas est d'utiliser les configurations de règles de pare-feu avancées qui permettent de bloquer automatiquement l'accès aux adresses IP qui établissent de nombreuses connexions. Malheureusement, ceci peut également impacter l'accès des « bons » robots.
Quelles sont les meilleures pratiques en matière de référencement lorsque l'on utilise le fichier robots.txt ?
Peut-être vous demandez-vous comment vous allez pouvoir utiliser un outil aussi complexe que robots.txt. Voyons tout cela plus en détail :
- Assurez-vous bien que vous ne bloquez pas un contenu ou une section de votre site qui doivent être explorés.
- Utilisez un mécanisme de blocage autre que robots.txt si vous voulez que l'équité du lien soit transmise d'une page avec robots.txt (c’est-à-dire pratiquement bloquée) à la destination de ce lien.
- N'utilisez pas robots.txt pour empêcher l’affichage des informations sensibles (comme les informations privées des utilisateurs) dans les résultats des moteurs de recherche. En effet, ceci pourrait permettre à d'autres pages de créer des liens vers des pages contenant des informations sur les utilisateurs, ce qui pourrait entraîner l'indexation de la page en question. +Dans cette situation, le fichier robots.txt a été contourné. D'autres options consistent à utiliser une protection par mot de passe ou la directive meta noindex.
- Il n'est pas nécessaire d’indiquer des directives spécifiques à chaque crawler car la majorité des agents utilisateurs appartiennent au même moteur de recherche et suivent les mêmes règles. Google utilise Googlebot pour les moteurs de recherche et Googlebot Image pour les recherches d'images. Le seul avantage qu’il y a à savoir comment préciser des directives pour chaque robot d'exploration est que vous êtes alors en mesure d'ajuster la façon dont le contenu de votre site est exploré.
- Si vous avez modifié le fichier robots.txt et que vous souhaitez que Google le mette à jour plus rapidement, soumettez-le directement à Google. Cliquez ici pour savoir comment procéder. Notez que les moteurs de recherche mettent en cache le contenu du fichier robots.txt et le mettent à jour au moins une fois par jour.
Les directives de base concernant le fichier robots.txt
Maintenant que vous comprenez les bases du système de référencement et de robots.txt, quels sont les éléments que vous devez garder à l'esprit lorsque vous utilisez robots.txt ? Dans ce chapitre, nous allons examiner quelques-unes des directives que vous devez suivre lorsque vous utilisez robots.txt, même s'il demeure important de lire toute la syntaxe.
Le format et l’emplacement
L'éditeur de texte que vous choisissez d'utiliser pour générer un fichier robots.txt doit pouvoir créer des fichiers textes ASCII ou UTF-8 standards. Il n’est pas recommandé d’utiliser un logiciel de traitement de texte à cause des risques d’ajout de certains caractères susceptibles d'affecter le crawling.
Vous pouvez utiliser n'importe quel éditeur de texte pour créer votre fichier robots.txt, toutefois cet outil est fortement recommandé car il permet de tester ce fichier sur votre site.
Voici d'autres directives concernant le format et l'emplacement :
- Le nom du fichier doit être « robots.txt ». Il est sensible à la casse et aucun caractère majuscule ne doit être utilisé.
- Vous ne pouvez avoir qu'un seul fichier robots.txt pour l'ensemble de votre site.
- Le fichier robots.txt ne peut se trouver qu'à un seul endroit : la racine de l'hôte du site auquel il s'applique. Il ne peut pas être placé dans un sous-répertoire. Si votre site est http://www.123.com/, l'emplacement de robots.txt doit être http://www.123.com/robots.txt, et non http://www.123.com/pages/robots.txt. Le fichier robots.txt peut s'appliquer à des sous-domaines (http://website.123.com/robots.txt) et à des ports non standard, comme http://www.123.com : 8181/robots.txt.
Comme indiqué plus haut, le fichier robots.txt n'est pas le meilleur outil pour empêcher l'indexation d'informations personnelles et sensibles. Il s'agit là d'une préoccupation légitime, en particulier depuis la récente mise en œuvre du GDPR. La confidentialité des données ne doit pas être compromise. Un point c’est tout.
Comment s'assurer que le fichier robots.txt ne dévoile pas d’informations sensibles dans les résultats de recherche?
Si vous voulez empêcher la distribution de matériel sensible, utilisez un sous-répertoire séparé « non listable » sur internet. Vous pouvez vous assurer que celui-ci n’est pas « listable » en vous rendant dans la configuration du serveur. Pour cela, il suffit de stocker dans ce sous-répertoire tous les fichiers que vous ne voulez pas voir inspectés et indexés.
Est-ce que l’inscription de pages ou de répertoires dans le fichier robots.txt peut accorder un accès involontaire ?
Comme nous l’avons déjà expliqué, le fait de placer tous les fichiers que vous ne souhaitez pas voir indexés dans un sous-répertoire distinct et d’empêcher qu’il soit répertorié (via la configuration du serveur) devrait les empêcher d’apparaître dans les résultats de recherche. Vous n’aurez alors qu’à inscrire le nom du répertoire dans le fichier robots.txt. Le seul moyen d'accéder à ces fichiers est d'établir un lien direct avec l'un d'entre eux.
Voici un exemple :
Au lieu de :
User-Agent:*
Disallow:/foo.html
Disallow:/bar.html
Utilisez :
User-Agent:*
Disallow:/norobots/
Vous devez ensuite créer un répertoire « norobots », qui inclut foo.html et bar.html. La configuration de votre serveur doit clairement indiquer qu’il ne faut pas générer de liste de répertoire pour le répertoire « norobots ».
Cette approche n'est pas très sûre, car même si les personnes ou les robots qui attaquent votre site ne peuvent pas voir le contenu de ce fichier, ils peuvent comprendre que vous possédez un répertoire « norobots ». Quelqu’un pourrait publier un lien vers ces fichiers sur son propre site internet et, pire encore, ce lien pourrait apparaître dans un fichier journal accessible au public (un journal de serveur internet en tant que référent, par exemple). Il est également possible de mal configurer le serveur, ce qui peut entraîner l'inscription d'un répertoire.
Ceci signifie que le fichier robots.txt ne peut pas vous aider à contrôler correctement l'accès à votre site internet, et ce pour la simple raison qu'il n'est pas conçu pour cela. C’est comme un panneau « interdiction d'entrée ». Certaines personnes entreront tout de même.
Si vous voulez que seules certaines personnes autorisées aient accès à des fichiers spécifiques, utilisez les configurations de serveur car elles vous aideront dans le processus d’identification de ces utilisateurs. Si vous utilisez un CMS (Content Management System), vous pouvez utiliser des contrôles d'accès sur les pages individuelles et la collection de ressources.
Peut-on optimiser le fichier robots.txt pour le référencement SEO ?
Tout à fait ! Le meilleur guide sur la façon d'optimiser robots.txt est le contenu du site. Petit rappel : Le fichier robots.txt ne doit jamais être utilisé pour empêcher l’exploration des pages par les robots des moteurs de recherche. Utilisez-le uniquement pour bloquer les sections de votre site internet qui ne sont pas accessibles au public, comme les pages de connexion tel que wp-admin.
Voici la ligne disallow pour la page de connexion de Neil Patel sur l'un de ses sites internet :
User-agent:*
Disallow:/wp-admin/
Allow:/wp-admin/admin-ajax.php
Vous pouvez utiliser la ligne « disallow » pour empêcher l’indexation de votre connexion.
S'il y a des pages spécifiques que vous ne voulez pas voir indexées, utilisez la même commande que ci-dessus. Par exemple :
User-agent:*
Disallow:/page/
Précisez quelle page vous ne voulez pas indexer après la barre oblique, et clôturez-la avec une autre barre oblique. Par exemple :
User-agent:*
Disallow:/page/thank-you/
Quelles sont les pages que vous souhaitez exclure de l'indexation ?
- Le contenu intentionnellement dupliqué. Qu'est-ce que cela signifie ? Il arrive que vous créiez intentionnellement du contenu en double pour une raison particulière. C’est ce qui arrive lorsque vous générez une version imprimable pour une page internet. Dans ce cas, vous pouvez utiliser le fichier robots.txt pour bloquer l'indexation de la version imprimable d'un contenu identique.
- Les pages de remerciement. La raison pour laquelle vous voulez bloquer l'indexation de cette page est très simple : elle est censée être la dernière étape du processus de vente. Au moment où vos visiteurs arrivent sur cette page, ils devraient avoir parcouru l'ensemble du parcours de vente. Si cette page est indexée, vous risquez de manquer de possibles ventes ou de recevoir de faux prospects.
La commande pour bloquer une telle page est :
Disallow:/thank-you/
Noindex et NoFollow
Comme nous l'avons répété plusieurs fois dans cet article, l'utilisation de robots.txt ne garantit pas à 100% que votre page ne sera pas indexée, alors examinons deux façons de s'assurer que la page que vous avez bloquée ne sera effectivement pas indexée.
La directive noindex
Cette directive fonctionne avec la commande disallow. Utilisez ces deux commandes dans votre directive, comme dans :
Disallow:/thank-you/
Noindex:/thank-you/
La directive nofollow
Elle permet d'indiquer spécifiquement aux robots de Google qu’ils ne doivent pas explorer les liens d'une page. Elle ne fait pas partie du fichier robots.txt. Pour utiliser la commande nofollow et bloquer l'exploration et l'indexation des pages, il vous faut trouver le code source de la page que vous ne voulez pas indexer.
Collez ceci entre les balises d'ouverture et de fermeture de l'en-tête :
<meta name = "robots" content="nofollow">
Vous pouvez utiliser simultanément « nofollow » et « noindex ». Utilisez cette ligne de code :
<meta name = "robots" content="noindex,nofollow">
Génération de robots.txt
Si la rédaction d’un fichier robots.txt vous pose un problème, à cause de la syntaxe particulière et des formats que vous devez comprendre et respecter, vous avez la possibilité de recourir à certains outils qui simplifieront ce processus. Parmi ces outils, il y a notre générateur de robots.txt gratuit.
Grâce à lui, vous pouvez choisir le type de résultat dont vous avez besoin sur votre site internet et le fichier ou les répertoires que vous souhaitez ajouter. Vous pouvez également tester votre fichier et évaluer comment se porte votre concurrence.
Tester votre fichier robots.txt
Vous devez tester votre fichier robots.txt pour vous assurer qu'il fonctionne comme prévu.
Utilisez le testeur de robots.txt de Google.
Pour cela, connectez-vous à votre compte webmaster.
- Puis sélectionnez votre propriété (votre site internet).
- Cliquez sur « crawl » dans la barre latérale gauche.
- Cliquez sur « robots.txt tester ».
- Remplacez tout code existant par votre nouveau fichier robots.txt.
- Enfin, cliquez sur « tester ».
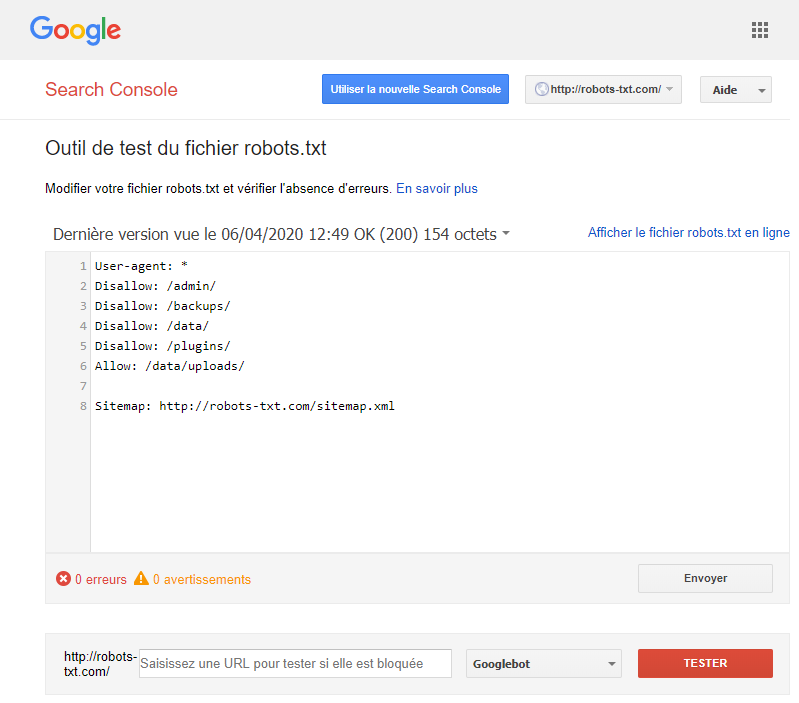
Si le fichier est valide, vous devriez alors voir apparaître une zone de texte « autorisé ». Pour plus d'informations, vous pouvez consulter ce guide approfondi sur le testeur Google robots.txt.
Si votre fichier est valide, vous pouvez maintenant le télécharger dans votre répertoire racine ou l'enregistrer dans un autre fichier robots.txt.
Comment ajouter le fichier robots.txt à votre site WordPress ?
Nous allons ici nous intéresser aux différentes options de plugin et de FPT qui vous permettront d’ajouter un fichier robots.txt à votre site WordPress.
Pour l'option plugin, vous pouvez utiliser un plug-in comme All in One SEO Pack.
Connectez-vous à votre tableau de bord WordPress.
Faites défiler les options puis allez sur « plugins ».
Cliquez sur « Add new ».
Allez dans « search plugins ».
Entrez « All in One SEO Pack ».
Installez-le, puis activez-le.
Dans la section « General Setting » du plugin All in One SEO, configurez les paramètres noindex et nofollow que vous devez inclure dans votre fichier robots.txt.
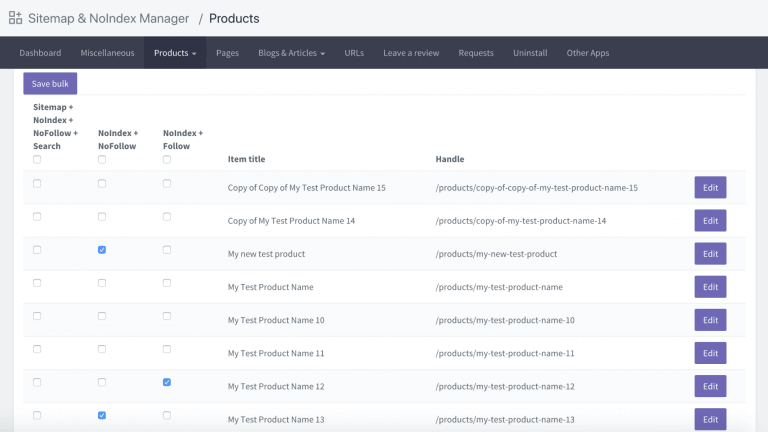
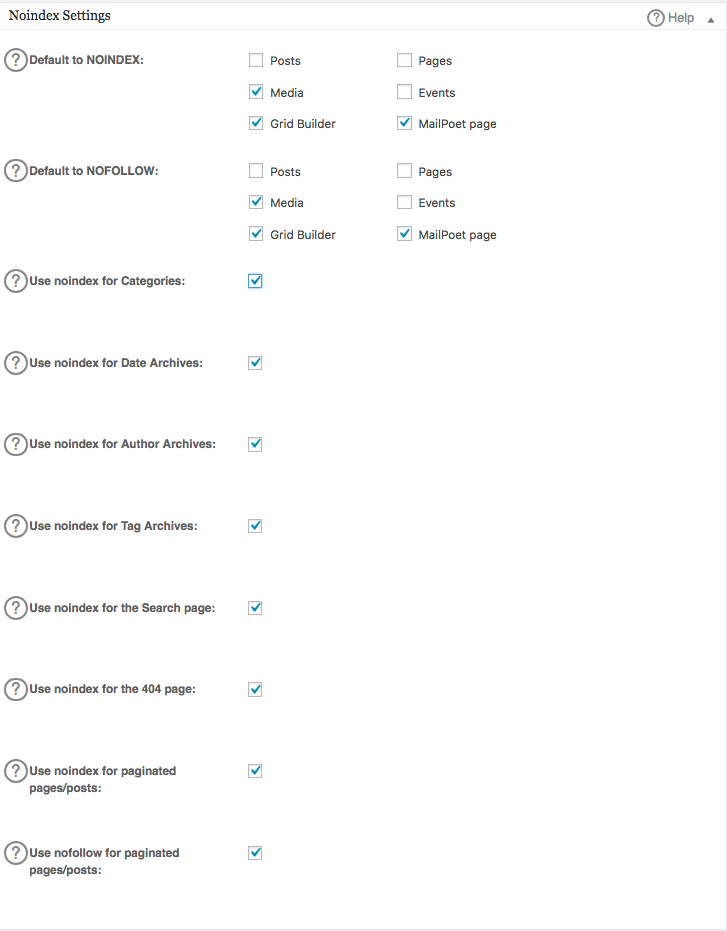
Vous pouvez préciser quelles URLs doivent être NOINDEX, NOFOLLOW. Les URL que vous ne cochez pas seront indexées par défaut :
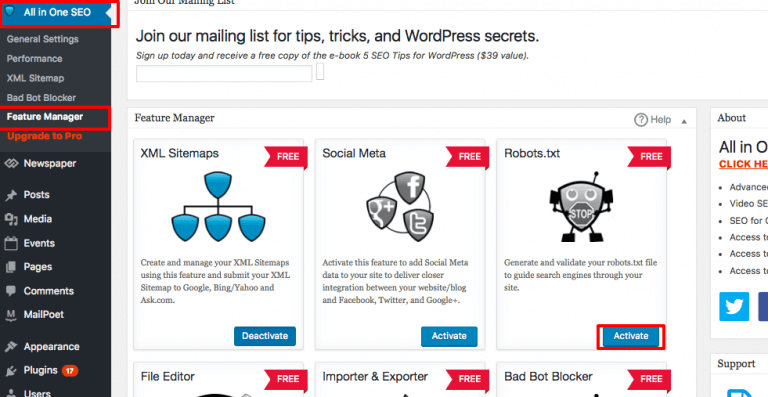
Pour créer des paramètres avancés dans votre fichier robots.txt, vous devez cliquer sur le gestionnaire de fonctionnalités, puis sur le bouton d'activation situé juste en dessous de robots.txt.
Le fichier robots.txt apparaît alors juste en dessous du gestionnaire de fonctionnalités. Cliquez dessus et vous pour voir apparaître une section intitulée « create a robots.txt ».
Une section de construction de règles vous permet de choisir et de remplir les règles que vous voulez imposer pour votre site, en fonction de ce que vous ne voulez pas indexer.
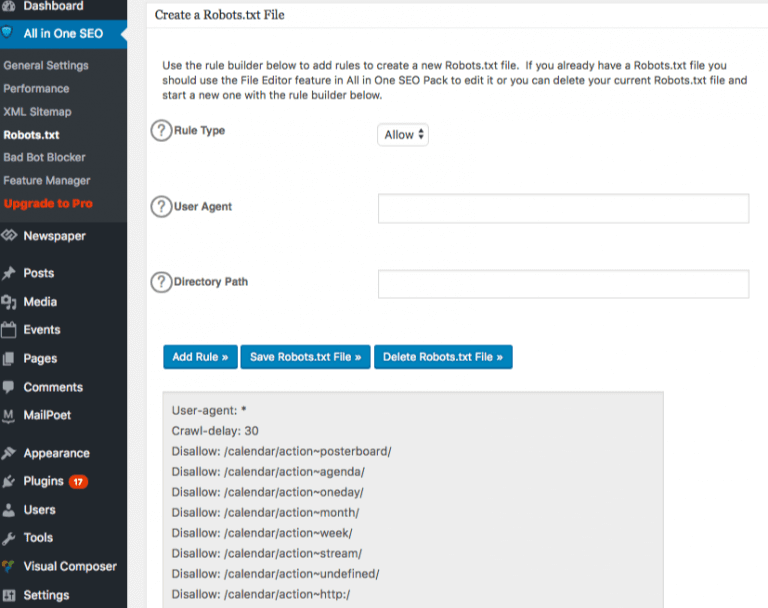
Maintenant que vous avez créé les paramètres, cliquez sur « add rule ».
La règle sera alors répertoriée sous le dossier robots.txt que vous avez créé.
Un message indiquant « Options All in One » apparaîtra pour vous indiquer qu’elles ont été mises à jour.
Une autre méthode consiste à télécharger le fichier robots.txt directement sur le client FTP (File Transfer Protocol) comme FileZilla.
Une fois le fichier robots.txt créé, vous pourrez le localiser et le remplacer. Votre fichier robots.txt se trouvera ici : « /applications/[NOM DU DOSSIER]/public_html ».
Comment modifier le fichier robots.txt de votre Wix ?
Wix génère un fichier robots.txt pour les sites internet qui utilisent leur plateforme de création de sites. Pour consulter ce fichier, il vous suffit d’ajouter « /robots.txt » à votre domaine. Les fichiers ajoutés à robots.txt sont rattachés à la structure des sites Wix, comme les liens noflashhtml, qui ne participent pas à apporter de la valeur en matière de référencement à votre site Wix.
Il est impossible de modifier le fichier robots.txt de votre site Wix. Vous pouvez utiliser d'autres options, comme ajouter une balise noindex aux pages que vous ne souhaitez pas voir indexées.
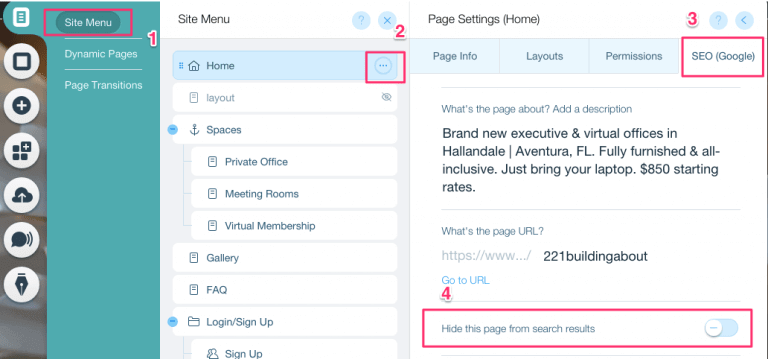
Voici comment créer une balise noindex pour une page spécifique :
- Cliquez sur le menu « Site ».
- Cliquez sur l'option « Setting » de cette page.
- Sélectionnez la balise SEO (Google)
- Activez l'option « Mask this page » dans les résultats de recherche
Comment modifier le fichier robots.txt de votre site Shopify ?
Tout comme avec Wix, Shopify ajoute automatiquement un fichier robots.txt non modifiable au site que vous créez. Si vous ne souhaitez pas que certaines pages soient indexées, vous pouvez soit ajouter une « balise noindex », soit dépublier la page. Vous pouvez aussi ajouter des balises méta dans l'en-tête des pages que vous ne voulez pas indexer. Pour ce faire, voici ce que vous devez ajouter à votre en-tête :
<meta name= "robots" content = "noindex">
Shopify a créé un guide complet pour expliquer comment cacher certqines pages aux moteurs de recherche.
Une autre option consiste à télécharger une application appelée Sitemap & NoIndex Manager, publiée par Orbis Labs. Vous pouvez tout simplement vérifier les options noindex ou nofollow pour chacune des pages de votre site Shopify :